

Analyze every alert automatically with Intezer — learn more or sign up to try for free here.
One of the greatest challenges security operations center (SOC) teams face is the high volume of daily alerts about suspicious files and endpoints that they must investigate. A lot has already been written about this “needle in the haystack problem.” SOC analysts are faced with so many alerts that they will likely miss the real threat (needle) hidden among the false positives (the haystack).
According to research published by the Ponemon Institute and reported in a Network World article, only four percent of alerts are truly investigated. It is nearly impossible to analyze every single alert coming through an organization due to time constraints and a lack of resources. As a result, many alerts remain uninvestigated. This is in contrast to a “zero-trust approach” that assumes every alert might indicate a breach and therefore must be investigated thoroughly.
The Zero-Trust Trust Approach to Alert Investigation
Sophisticated attackers understand that defenders have many alerts to investigate. Many successful cyber attacks are the result of security teams missing an alert because the alert “haystack” was too large. In addition, advanced attacks may be hidden behind vague alerts such as “suspicious behavior” which are often missed or go ignored. This further supports the notion that no alert should be left uninvestigated.
For that reason, it is important for security teams to embrace a zero-trust approach when investigating alerts and to not compromise on investigating only a handful of alerts. A few solutions have been commonly adopted that are helping security teams address a greater number of alerts, which we will divide into two categories: alert reduction and response automation. When integrated properly, alert reduction and response automation should help defenders reduce the greater “haystack,” in other words lowering the number of alerts that need to be investigated by a security team.
Leveraging Automated Triage and Threat Clusters for Alert Reduction
Alert reduction means narrowing down the “pile” of alerts that need to be investigated, weeding out noise and false positives so you can cluster the remaining threats.
This is done by automatically collecting evidence and investigating alerts, obtaining enough data (extracting files, URLs, etc.) to cluster threats and correlate events. This makes the investigation process more efficient by reducing the number of total alerts that need attention and providing greater context into all your alerts.
Here’s an example from one of Intezer’s reports, summarizing triaged alerts from the previous week and visually breaking down the “alert haystack”:
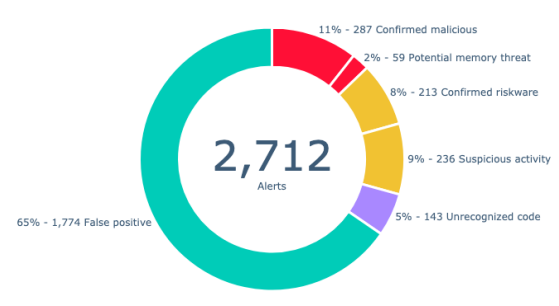
Let’s give an example with threat clusters – you take all the new alerts from just today, triage them, filter out the false positives, and find you have 17 threat clusters, 3 alerts that need investigation, and 2 “unknown” alerts. This clustering gives you a lot of information about how you can efficiently respond to the known threats and which ones might require action first.
Here’s what those threat clusters would look like:
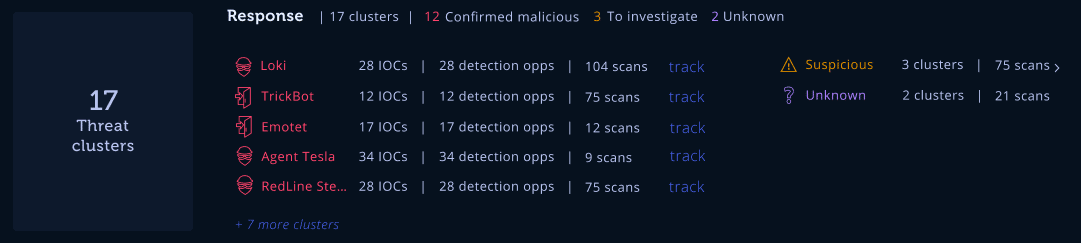
If you started with hundreds or thousands of alerts, automatically identifying false positives then grouping remaining alerts into threat clusters it is much less overwhelming. This kind of automated triage saves teams time and ensures each alert gets the appropriate investigation and response.
Response Automation for Clustered Alerts
Response automation is used to take action, automatically investigating further, triggering auto-resolution, and only escalating serious threats. Response automation allows security teams to automate alert triage and accelerate response, concentrating their efforts on threat clusters or threats that require hands-on response. We can see that in our example image above, we have the IoCs and detection opportunities for each cluster.
For example, once “suspicious behavior” is detected, response automation can be used to automatically trigger live memory analysis to scan for fileless malware or other in-memory threats. By using automation, you can reduce the manual steps you need to take to go from getting the alert through triage, investigation, and response. This is a key way for teams to reduce incident response time.
The Challenges of Investigating Every Suspicious Alert
Alert reduction and response automation can be helpful for reducing the workload required for investigating such a large volume of alerts. The challenge remains if a technical analyst is needed to manually analyze the suspicious alerts, as can happen after teams try automating such processes with SOAR playbooks.
Some tasks, unfortunately, are very difficult to automate. Reverse engineering, for example, is typically not a task that can be performed automatically and at scale. The same applies for memory analysis. In the past, a team of malware analysts was often required to perform a deeper analysis of alerts in order to better understand and classify them. For example, you may need human analysts to figure out:
- Is the alert a false positive?
- If the alert is a threat, what type of threat is it?
- What is the intent and sophistication level of the threat?
- Who is the threat actor behind the attack?
Unfortunately, the majority of organizations do not have access to a large, dedicated team of reverse engineers who can provide a deeper analysis on every single suspicious alert. However, with a smart alert triage solution, teams don’t necessarily have to rely on traditional malware analysis tools and sandboxes. Updating DFIR tools can also help teams close skill gaps, allowing analysts who don’t have extensive experience to quickly analyze suspicious alerts and respond without manual reverse engineering or malware analysis.
In an ideal world, we would deeply analyze every single alert.
For example, if there is an alert on a specific endpoint within an organization, we would want to analyze every file in the file system and every single module in memory. In other words, we’d execute a deep investigation on the machine as a whole.
Achieving the Goal of Investigating Every Alert
Imagine that you have a team consisting of several dozen reverse engineers, who can analyze every file and every memory image of suspicious endpoints that have been alerted through your security systems. Every phishing email and attachement too. This team of experts will be able to answer the most relevant questions about each and every alert that you encounter:
- They would need to answer, are we facing a real attack?
- To better understand the risk of the attack, which type of attack are we dealing with? (Is it adware or an APT, for example.)
- They will tell you the intent of the attacker. For example, by identifying a threat as ransomware or a banking trojan.
- They will be able to tell you if the threat is related to an incident that you had previously, which is important for building greater context behind a malware campaign.
- Which machines are infected and what is the scale of the attack?
- How do we contain and remediate the threat?
This scenario, where you have the budget for experts to analyze every alert, is ideal.
However, transitioning back to reality, how is this scenario achievable? How can we as security professionals automate the skills of experienced reverse engineers into our day-to-day security operations, to automatically and deeply investigate every alert that comes through our SIEMs, SOARs, or EDRs? What about investigating the constant stream of phishing alerts?
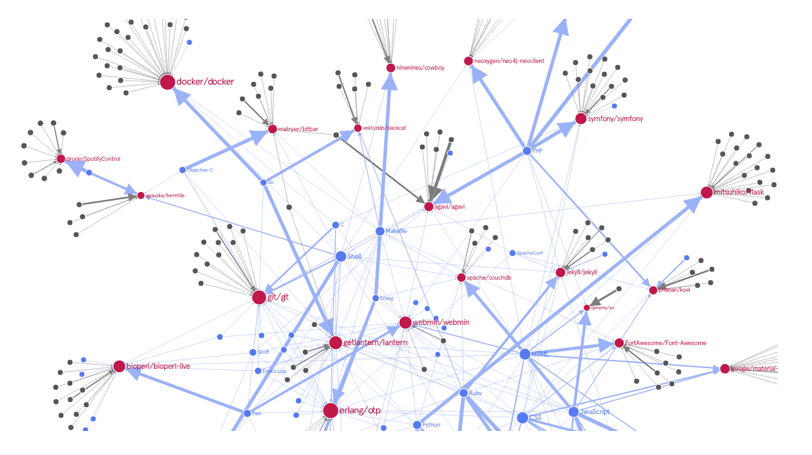
Clusters of Reused Malicious Code
The above graphic is a mapping of code reuse and code similarities across various open-source projects. Legitimate projects consistently reuse code from other projects.
Now let’s take a look at the following graphic:

Every node in the layout represents a malware campaign that is associated with North Korea. There are code similarities between the WannaCry ransomware in 2017, the Sony attack from 2011, and also the Swift Bangladesh attack from 2016.
We see this common phenomenon of code reuse in both trusted and malicious software. It is a very logical progression for developers to reuse code. Reusing code is not inherently malicious. Leveraging code reuse makes the lives of developers more convenient and efficiently brings tools to the market faster.
How Can Code Reuse Accelerate SOC and IR Workflows?
From a practical viewpoint, as defenders how can we utilize the concept of code reuse for our own benefit?
Intezer uses propriety analysis technology to detect even the smallest trace of code reuse. Applying this genetic code reuse approach to alert triage, malware analysis, and incident response means identifying code similarities of known trusted and malicious software, in order to detect threats and reduce false positives.
Even if an attacker decides to write most of his or her code from scratch, as long as some portions of the code are reused from previous malware, which we see in almost all cases, Intezer can detect any future variant, regardless of evasion techniques that may be deployed.
By breaking software into “genes”, like small fragments of DNA, you can also understand which portions of the code are trusted or malicious. The same principle applies for code that was seen in legitimate, trusted applications, which can be used to identify false positives and in turn reduce the overall “alert haystack.”
Alert reduction and response automation solutions help to cluster and greatly reduce the number of alerts that must be investigated. Organizations cannot compromise on investigating only a handful of alerts while ignoring the rest, without running the risk of serious incidents slipping through the cracks. SOC and IR teams can improve their efficiencies by leveraging automation technologies in tandem with time-saving analysis technologies, in order to investigate every single alert quickly and garner relevant context that will help them to prioritize, tailor, and accelerate their response.
The ultimate goal of code similarity analysis (or, “Genetic Code Analysis” aka the heart of Intezer’s technology) is to automate the alert triage, incident response, and threat hunting processes, in order to move closer to the ideal world that we described earlier, where organizations can accurately analyze every single alert quickly and automatically, and respond with greater confidence to a higher volume of alerts.
Connect your alert pipelines (EDR, phishing emails, SOAR, SIEM, …) to Intezer, so you can automatically triage, investigate, and respond.
Want to see how it works? Let’s book a demo.

Count on Intezer’s Autonomous SOC solution to handle the security operations grunt work.
Recommended Articles
-

How Artificial Intelligence Powers the Autonomous SOC Platform
A few years ago leading cybersecurity professionals and industry analysts were publicly saying that... 7 March 2024 -
Interactive Browsing: A New Dimension to URL Analysis
We’re excited to announce a new feature in Intezer that revolutionizes how security teams... 26 February 2024 -
Real Time Feedback: Fine-Tuning Autonomous SOC to Your Environment
Continuous improvement is a requirement in the ever-evolving cybersecurity space. That’s why Intezer is... 7 February 2024


