This article is based on joint research with Eran Segal, researcher at Kodem Security.
The most capable commercial AI models are now useful enough to attackers that they have become an integral part of their kill chain, in multiple steps. The Cybench benchmark tests models on offensive cyber tasks. Its current top performers (Claude Opus 4.6, Claude Sonnet 4.5, Grok 4) can write functional exploit code, reason through credential chains, and sustain complex reconnaissance workflows: multi-step offensive work that previously required human expertise. Malware families are already using this. Instead of generating a payload offline and shipping it, they wire a live LLM API into the malware itself so it can adapt its behavior at runtime on the infected host.
Commercial providers run abuse detection and terminate accounts linked to malicious activity. A payment method creates a paper trail that investigators can follow. So attackers solve the access problem the same way they solve any resource problem: they steal it, find it free, or find it unguarded.
This post covers five routes threat actors use to reach LLM inference without paying for it: buying offensive models on underground forums, using front-end models using 3rd party LLM service that allows paying in bitcoin, using free-tier or keyless public APIs, hunting for leaked API keys in developer artifacts, and exploiting self-hosted LLM servers left open on the internet.
Method 1: Offensive LLMs and Anonymous Payment
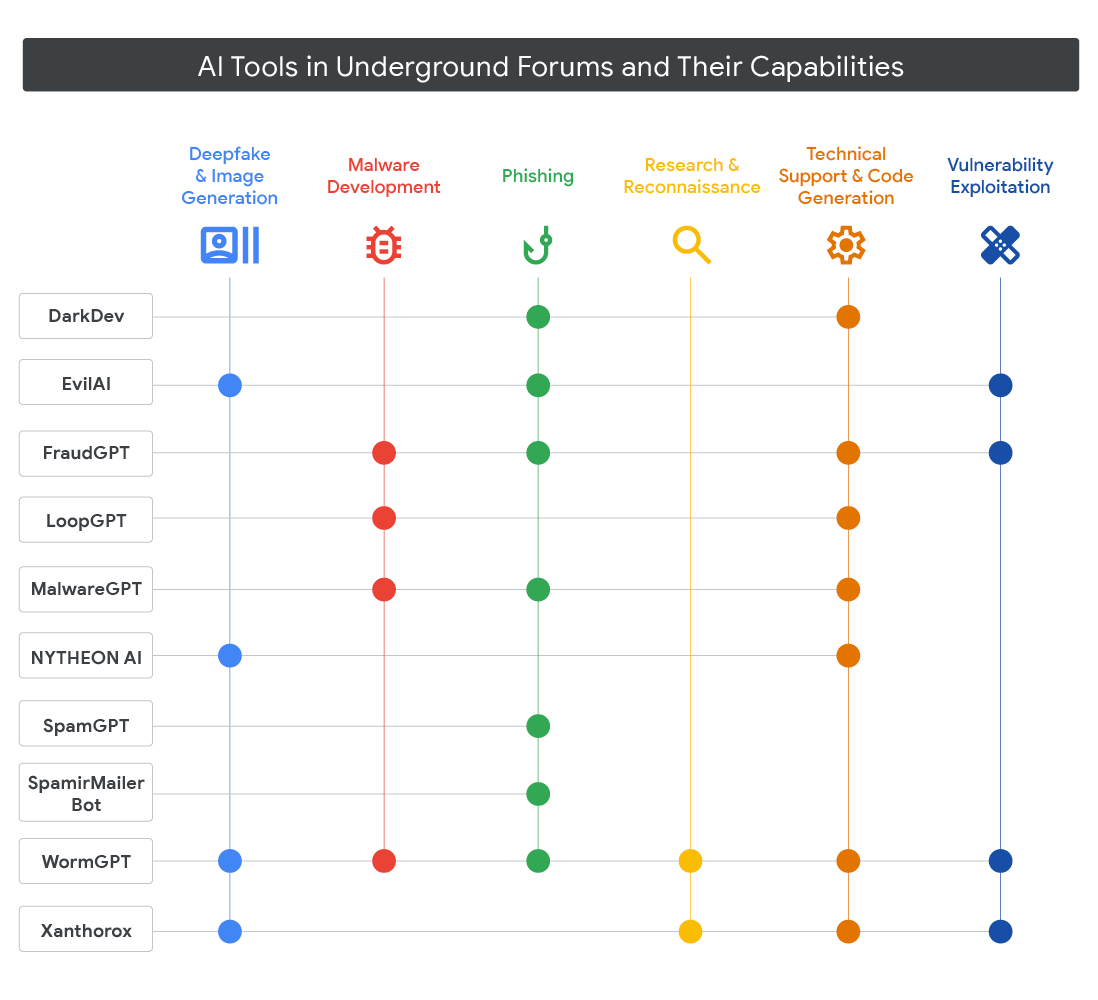
Cyber-oriented LLMs sold on underground forums are the most visible route. WormGPT, GhostGPT, KawaiiGPT, and Xanthorox are the most cited examples, covered in depth by Unit 42. These are returned open-weight models or jailbroken wrappers over commercial APIs, marketed specifically as having no content filter. They solve the moderation problem but not the cost problem: access is sold on a subscription basis, and the capability ceiling sits well below that of frontier commercial models. So they are useful for generating phishing content or simple malware stubs, but less so for the kind of autonomous multi-step offensive work that the frontier models in the Cybench ranking are capable of.
Method 2: Using Frontier Models Through a Third-Party Service
If a threat actor would like to use the frontier models to achieve top performance, they can still use these models using 3rd party services such as PayWithMoon and AIMLAPI.
These services sit between the attacker and a commercial LLM provider, accepting cryptocurrency without identity verification and then funding a legitimate provider account on the attacker’s behalf. The account itself reaches frontier models, but the funding trail stops at the middleman. The account will still get burned once abuse detection triggers, but replacing it is cheap. The upstream provider has no usable identity to pursue. This is how attackers buy frontier-model access while skipping the paper trail a normal commercial account would leave behind.
Method 3: Free-Tier and Keyless Public Inference APIs
A cheaper alternative to underground subscriptions exists in plain sight. Most major inference providers publish permanent free tiers that require nothing more than a disposable email address, and a handful of services accept requests with no credentials at all. An attacker who registers for a pool of free-tier accounts gets as meny tokens as he wishes without paying a dime.
The scale of the free-tier ecosystem is easy to measure because the community has cataloged it. Public curated lists such as cheahjs/free-llm-api-resources and mnfst/awesome-free-llm-apis explicitly filter for providers that offer a permanent (not trial-credit) free tier with no credit card. Representative entries, with numbers pulled from each provider’s own rate-limit documentation:
- Groq: 30 requests/minute (RPM) on all free-tier models, with requests/day (RPD) caps ranging from 1,000 (for the 70B llama) to 14,400 (for the 8B llama).
- Cerebras: 30 RPM, 14,400 RPD, and roughly 1M tokens/day on three of the four free-tier models (gpt-oss-120b, llama3.1-8b, qwen-3-235b).
- Cohere: 20 RPM on the Chat API and a hard cap of 1,000 total API calls/month on a trial key.
- Mistral La Plateforme: 1B tokens/month on the Experiment plan. No credit card is required, but a verified phone number is required, which is the highest sign-up friction in this group.
- HuggingFace: Free accounts are rate-limited on both the Hub API and the Inference API per 5-minute window. Anonymous per-IP access exists but is stricter than the free-account path.
- OpenRouter: 50 free model RPD with no deposit at all, and 1,000 RPD after a one-time $10 top-up that is never spent against model usage.
- SambaNova: 20 RPM and 20 RPD, with a 200,000 tokens/day cap. The tightest daily request ceiling in this group by a wide margin.
These providers differ in rate limits, models, and throughput. What they share is that a usable credential requires nothing more than a disposable email address (a phone number in Mistral’s case) and no payment method. Credentials can simply be rotated when limits are reached.
The fully keyless end of the spectrum is thinner, but it exists. Pollinations.ai exposes an OpenAI-compatible endpoint that accepts requests with no authentication for basic use. DuckDuckGo’s Duck.ai anonymizes browser-based access to Claude 3.5 Haiku, Llama 4 Scout, Mistral Small 3, GPT-5 mini, and GPT-4o mini with no account at all. These services are not designed for bulk programmatic use, but they are reachable from any HTTP client, and the only cost is rate-limit friction.
Among the malware families in the intro table, LameHug/PROMPTSTEAL is the cleanest example of this route in the wild: it calls HuggingFace’s Inference API for Qwen 2.5-Coder-32B-Instruct to drive reconnaissance and data theft, with no embedded credentials reported by Splunk. Whether the malware carries a token or registers one at runtime is not established, but either way, the enabling property is HuggingFace’s no-credit-card free tier.
Method 4: Exposed API Keys
The fourth route to free model access doesn’t require finding an exposed server at all. Developers routinely hardcode credentials directly into apps, config files, and scripts. These credentials can be found in GitHub in open-source projects, while closed-source projects contain the credentials in the app itself. These artifacts are submitted to VirusTotal when apps are submitted for malware analysis. It can be an APK, ELF, EXE, or any type of artifact shipped with the product.
To find them systematically, we wrote a YARA rule targeting the key formats of the major AI providers: Google Gemini (AIzaSy…), OpenAI (sk-…), Anthropic (sk-ant-…), HuggingFace (hf_…), Replicate, Mistral, Cohere, Groq, and several others. We ran the rule as a retrohunting query across the VirusTotal corpus, collected the matching sample hashes, then pulled the raw files and ran a regex extraction pass to extract every key-value pair, provider, and surrounding code context. From there, we enriched each sample with VirusTotal metadata to understand detection rates and file types. The final step was validation: a lightweight GET request against each provider’s model-list or whoami endpoint. No prompts sent, just a check of whether the key authenticates.
The corpus yielded 647 unique keys across all providers. Roughly 62% were Google Gemini (AIzaSy…) keys. That concentration traces back to the Android developer ecosystem, where apps built for translation, search, or chatbot features commonly bundle the key directly in compiled resources or Java code. HuggingFace keys made up about 11%, Replicate about 8%, OpenAI sk- keys about 7%, and the remaining share was split across Voyage (5%), Mistral (3%), and Cohere (3%), with trace amounts of Anthropic, Groq, and OpenAI environment-style keys. The Mistral and Cohere keys concentrated heavily in a single file: a cracked “Collins Italian Dictionary MOD” Android APK that bundled 20 Mistral keys and 15 Cohere keys alongside 2 Gemini keys, with the small remainder scattered across two versions of a Ubisoft game APK.
About 65% of the 659 unique samples are confirmed Android by VirusTotal’s type classification. Another 18% are ZIP archives that follow the same submission pattern but were not explicitly tagged as Android. The true APK share sits between 65% and 84%. The remainder consisted of Windows PE files (5%), HTML pages, Python scripts, plain-text credential dumps, and a handful of Mach-O and ELF binaries. That Android skew isn’t surprising. APKs are frequently submitted to VirusTotal for modding and repackaging, and their keys remain intact after decompilation.
We submitted research samples to Intezer Analyze for code-based attribution, and three entries stand out. Four samples whose filenames suggested Akira ransomware are three Mimikatz binaries (1, 2, 3) and one malicious binary without family attribution, all credential-dumping tools that happened to carry API keys. The sample with a HuggingFace key is SolarMarker, an SEO-poisoning backdoor with infostealer capability. A Windows binary named SystemSettings.exe contained OpenAI, Replicate, and Voyage keys; the multi-key combination is more consistent with theft from a developer’s machine than with intentional hardcoding.
When we ran the validation, almost all the keys were dead. The revocation rate was approximately 99.5%, consistent with a corpus skewed toward older samples that had been on VirusTotal long enough to be detected, rotated, or simply expired. The small fraction that remained live consisted entirely of Google Gemini keys from Android APKs. All appeared to be genuine developer mistakes rather than exfiltrated credentials: a key embedded in a const in bundled JavaScript, one in a logging module in a compiled Android class, and one in a utility app’s APK resources. Those three keys have been reported to Google.
The method also illustrates why embedding API keys in client software is a particularly bad idea. Extracting a key from an APK requires a decompiler, and APKs have a reliable path to VirusTotal: users submit them for malware checks, repackaged versions circulate through third-party stores, and cracked builds get flagged automatically. The near-total revocation rate strongly suggests that LLM providers scan VirusTotal for their own key formats and automatically revoke matches. The three keys that were still live were all recent submissions, not yet caught by that sweep. If that pipeline exists, embedding a key in client-side code is not just a security mistake, but a futile one, and the key will likely be dead before it can be abused at scale.
The takeaway for an attacker is that hunting VirusTotal for hardcoded keys is low-effort but low-yield. The more durable access method is the exposed LLM server. A server running vLLM (a popular open-source LLM inference framework) or an open Ollama instance requires no authentication, doesn’t rotate anything while in use, and the owner usually doesn’t know it’s happening.
Method 5: Hack Public LLM Hosting Servers
Self-hosted LLM platforms make it easy to run your own models on your infrastructure, and that same ease extends to anyone who can access the port. Most ships have no authentication by default and expose administrative endpoints that let a stranger list installed models, queue inference jobs, load new models from remote URLs, or, in several cases, execute code on the host. When the server is exposed to the public internet, the attacker does not need a stolen key or a forum subscription. The victim is paying the GPU bill, carrying the API-key spend, or hosting the RCE.
We scanned roughly 4,500 hosts across eleven of them. Every service had open instances, and 14 LocalAI hosts showed active compromise based on attacker-loaded model names consistent with a single automated campaign. The sections below cover what each platform is, how exposure gets abused, and what the scan found in the wild.
Ollama
Ollama runs open-weight LLMs locally. By default, it binds to 127.0.0.1, and the authentication is disabled. But setting OLLAMA_HOST=0.0.0.0 is a common step when accessing it from another machine on the network or from a frontend app running in a separate container. It exposes all interfaces, and anyone reaching it’s port gets full API, model management, and hardware access. SentinelOne Labs and Censys already published the definitive survey, documenting 175,000+ hosts chained into anonymous AI networks for free text, embedding, and bulk content generation on victim hardware. That pattern is now commercialized by Operation Bizarre Bazaar, which sells subscription access to a unified LLM gateway fronted by stolen Ollama endpoints, turning ad-hoc LLMjacking into a growing concern.
LocalAI
LocalAI is an OpenAI API-compatible model server supporting LLMs, image generation, speech, and transcription. Authentication is disabled by default. It also supports remote model installation, P2P distributed serving, and a built-in agent platform with support for MCP. Of all the services in this research, it has the widest attack surface.
Of all the hosts scanned, 55% were confirmed open, the highest absolute count in this group. About 24% are API proxies with live upstream keys for OpenAI, Anthropic, and Google accessible to anyone who can reach the host.
The most striking finding is evidence of automated exploitation at scale. About 21% of confirmed hosts carry model names with a consistent signature tied to ProjectDiscovery’s nuclei scanner templates, with per-run timestamps mapping to late March and early April 2026. The pattern is consistent with automated scanning for an unauthenticated remote code execution path, in which a malicious URL supplied during model installation triggers server-side code execution. The exploit payload appears to load a small publicly available Italian-language model as a “hello world” confirmation, which recurs on every affected host. The markers not being cleaned up argue against mature attacker tradecraft. Operators running LocalAI can open /v1/models on their own host: any nuclei-rce-* or rce_<timestamp> identifier is not human-chosen and indicates this campaign hit them.
Langflow
Langflow is a visual builder for multi-agent AI pipelines, widely used to prototype RAG systems and chatbots. Flows routinely embed hardcoded credentials: OpenAI and Anthropic API keys, database connection strings, Slack tokens, and webhook secrets. Anyone who can reach the host and read a flow config has all of them. Unlike the previous examples, this app does not have a known major misconfiguration, but it does not prevent attackers from being able to hack and gain access to this service. For example, two unauthenticated RCE bugs make reaching the config trivial:
- CVE-2025-3248:on the CISA KEV list, reliably patched only in 1.6.4+
- CVE-2026-33017: fixed in 1.9.0, exploited in the wild within 20 hours of disclosure.
Every confirmed host in our scan ran a version vulnerable to CVE-2026-33017; about 72% were also vulnerable to CVE-2025-3248. Several hosts didn’t authenticate at all, with flows, credentials, and both RCE paths openly accessible. Code execution on the Langflow host is the small prize. The keys inside the flows pivot to everything the workflows connect to.
n8n
n8n is a low-code workflow automation platform with 400+ service connectors and code execution nodes (workflow steps that run arbitrary scripts). It has the strongest default auth posture of any service in this research: User Management is enforced on fresh installs.
But it does not prevent attackers from actively gaining access to n8n. Vulnerabilities such as CVE-2026-21858 (“Ni8mare”, CVSS 10.0, fixed in 1.121.0), which is a vulnerability in the web hooks request handling that turns exposed endpoints into a full unauthenticated RCE surface via content-type confusion, with a public PoC already out. Prior research estimates the exposed n8n population at tens of thousands of hosts.
The post-exploitation story mirrors Langflow. Workflows carry hardcoded API keys, database connection strings, and webhook secrets. RCE on the n8n host effectively gives access to every system the automations touch.
vLLM
vLLM is a high-throughput LLM serving engine with GPU acceleration, commonly used to self-host open-weight models in production. It exposes an OpenAI-compatible REST API. Authentication requires an explicit –api-key flag; without it, the API is open.
The interesting finding from our scan was not vLLM itself but the adjacent deployments surfaced by the same query: OpenAI-compatible HTTP proxies, specifically LiteLLM-style gateways that aggregate multiple paid providers behind a single endpoint. These proxies store live API keys for OpenAI, Anthropic, Google, Groq, and Cohere. None had protection on the model list endpoint. One host exposed 35 models across multiple providers; several listed exclusively Anthropic Claude models. A proxy returns a model list only when the upstream provider authenticates, so every successful response confirms the underlying keys are live and billable.
The abuse path is trivial: point any standard OpenAI SDK client at the proxy, enumerate the models, and, on hosts where prompt submission is also unprotected, send requests billed to the operator’s accounts. It is the same credential-pivot pattern as Langflow and n8n.
ComfyUI
ComfyUI is a node-based workflow UI for Stable Diffusion, video generation, and multimodal image models. It runs on high-end GPU hardware with no authentication by default, making it a direct target for attackers looking to steal GPU compute.
Our scan found open instances across a wide range of versions (v0.2.2 to 0.19.0), all of which were fully unauthenticated. The hardware exposure is the headline finding. Open hosts reported a combined ~4.3 TB of GPU VRAM, with cards ranging from RTX 4090s and RTX 5090s to datacenter-grade A100S and L40S units, each worth tens of thousands of dollars. An attacker can queue generation jobs against any of them at no cost.
Beyond compute theft, 95% of open hosts expose a job history endpoint that leaks previously executed workflows, local file paths, and prior user content. About 12% advertise URL-loading nodes that act as server-side request forgery primitives: usable for internal network reconnaissance or cloud metadata credential theft.
llama.cpp server
llama-server is the HTTP server shipped with llama.cpp, commonly used to serve a single open-weight model in production. It has no authentication by default, no access controls on the inference endpoint, and a metadata endpoint that advertises exactly what the host is running. Anyone who reaches the port can submit prompts, watch active jobs, and burn the operator’s GPU on their own workload. Classic LLMjacking, with the bonus of knowing exactly which model they are running.
Of scanned hosts, 59% were confirmed open, more than any other platform in the scan. Everyone exposed its model name and hardware configuration, and about 37% also leaked real-time job state, confirming the host was actively serving users at the time of the scan. The models observed were standard open-weight builds rather than anything exotic, which is the point. An attacker is not looking for a rare model, just an unattended GPU.
Jan
Jan is an Electron desktop AI app with an optional OpenAI-compatible API server on port 1337. When enabled, it binds to all interfaces with no authentication. Jan is a useful example of how exposure surfaces unexpected content rather than how common it is. Our scan confirmed only two genuine Jan hosts. Both had gone offline by the rescan a week later. While one was live, it exposed a 35-model library that included miqu-70b; a leaked Mistral Medium prototype that was never officially released. When a desktop app binds its API server to the public internet, whatever model (or file path metadata) sits on the operator’s disk becomes visible.
Gradio
Gradio is a Python framework for building ML demo apps: image classifiers, code interpreters, document Q&A, or anything a researcher can wrap in a web UI. Exposure risk depends entirely on what the underlying app does. A sentiment-analysis demo is low-stakes. An app that accepts file uploads, runs user code, or queries a database is a direct path to exploitation. The Gradio queue keeps processing submitted requests whether the operator is watching or not, so abuse can run quietly for days.
Three unauthenticated bugs make unpatched instances worse:
- CVE-2024-1561: arbitrary file read, fixed in 4.13.0
- CVE-2024-0964: path traversal, fixed in 4.9.0
- CVE-2024-47084: CORS validation bypass, fixed in 4.44.0; a malicious website can reach a locally running Gradio server while the victim is still logged in
Ranking the Five Routes
Each route carries operational trade-offs. The table below scores each on five dimensions, ranging from 0 (least favorable) to 5 (best for attacking): non-resistance (refusal behavior in response to offensive prompts), model capability (coding ability and parameter count), tool and MCP support, and effective token quota.
| Route | Non-resistant model | Model capability | Tool / MCP support | Token quota | Cost |
|---|---|---|---|---|---|
| Offensive LLMs (WormGPT, GhostGPT, crypto middlemen) | 5 | 3 | 5 | 2 | 2 |
| Crypto payment for frontier | 2 | 5 | 5 | 5 | 3 |
| Free-tier and keyless public APIs | 2 | 4 | 4 | 3 | 5 |
| Stolen or leaked API keys | 1 | 4 | 5 | 1 | 5 |
| Exposed LLM servers | 5 | 3 | 3 | 5 | 5 |
Offensive LLMs score highest on non-resistance. But the underground-forum variants sit well below frontier models in capability and tool support, and subscriptions cap the quota. The crypto-middleman variant reaches frontier models via real provider accounts, but those accounts burn quickly once abuse is detected.
Crypto payment for frontier models is for sure the best way to gain access for the most capable models with the ability to connect the model to any interface, such as MCPs, but it comes with some risks that the model might resist the action or the user will be blocked.
Free-tier and keyless public APIs score well in capability and tool support, with full-function calling across most providers. The per-account quota is modest, tens of RPM, thousands of RPD, but trivial account rotation pushes the effective quota well above the face value.
Stolen or leaked API keys, in principle, offer the best combination of capability and tool support; the retrohunt’s 0.5% live rate shows the real-world quota is near zero.
Exposed LLM servers score highest on non-resistance and token quota. Non-resistance is unconstrained: the attacker controls model selection, and our scan found at least one LM Studio host actively serving llama3.3-8b-instruct-thinking-heretic-uncensored-claude-4.5-opus-high-reasoning-i1. Token quota is equally unconstrained, bounded only by the victim’s hardware rather than a billing cap. Capability and tool support vary by host, but that variance is what makes the route durable at scale. No individual host needs to run a frontier model.
The scoring explains why exposed servers are the most durable route, even though they don’t top every dimension. They are the only route where non-resistance and token quota both max out. The other three are each compromised on at least one of those two axes.
Cases Found in the Wild
Threat actors are now wiring malware to live LLM APIs, using them to generate malicious logic at runtime rather than embedding static code in the payload. Instead of scripting separate execution flows for different host conditions, the malware queries an LLM while running, determines whether the target appears to be a personal machine, a server, or an industrial controller, and then generates tailored commands or code accordingly. This shift matters because dynamically generated logic has no fixed signature to detect. Researchers have identified five malware families doing this.
| Malware name | Capabilities | AI Provider | Runtime model source |
|---|---|---|---|
| MalTerminal | Reverse shell or ransomware generation | OpenAI GPT-4 (deprecated chat completions endpoint) | Hardcoded API key |
| LameHug/PROMPTSTEAL | Reconnaissance and infostealer | Qwen 2.5-Coder-32B-Instruct via HuggingFace | Public HuggingFace Inference API (no embedded key observed) |
| Ransomware 3.0/PROMPTLOCK | Ransomware with exfiltration and wipe capability | gpt-oss-20b | Local Ollama API on the infected host |
| PROMPTFLUX | Dropper with AI-driven polymorphism | Google Gemini (gemini-1.5-flash-latest) | Hardcoded API key |
| QUIETVAULT | GitHub/NPM token stealer that uses AI to find additional secrets | Whatever AI CLI is installed on the victim (provider not named) | AI CLI tools already on the infected host |
MalTerminal and PROMPTFLUX both use a hardcoded API key to connect to a commercial provider when needed. MalTerminal uses OpenAI GPT-4 via the now-retired chat-completions endpoint to create reverse shells or ransomware. PROMPTFLUX connects to Google gemini-1.5-flash-latest to rewrite its own VBScript source code between runs, making it harder to detect.
LameHug, also known as PROMPTSTEAL, uses HuggingFace’s Inference API to run Qwen 2.5-Coder-32B-Instruct for Windows commands to support reconnaissance and data theft. HuggingFace requires an API token for each request, but free accounts don’t need a payment method and allow a few hundred requests per hour per API token. Attackers can easily create and rotate these API tokens, giving them the same access as stolen keys but with less hassle.
PROMPTLOCK is a proof-of-concept AI-powered ransomware prototype, often called “Ransomware 3.0,” developed by researchers at NYU’s Tandon School of Engineering. The Go binary invokes gpt-oss-20b via a local Ollama API running on the infected host to generate Lua scripts that perform file listing, encryption, exfiltration, and (unfinished) wipe logic. This is a bring-your-own-model: no outbound calls, no provider-side billing trail, and no way to scale beyond the victim’s own hardware.
QUIETVAULT is a credential-theft variant. The JavaScript stealer exfiltrates GitHub and NPM tokens to an attacker-controlled GitHub repo and then hands off the filesystem search for additional secrets to whatever AI CLI is already installed on the victim, so the stolen credentials are an active on-host AI session rather than a bare API key.
Looking at the four main routes discussed in this post, LameHug/PROMPTSTEAL is the best example of the free-tier method, since it calls HuggingFace’s Inference API directly. MalTerminal and PROMPTFLUX both use hardcoded API keys, but it’s unclear where those keys came from, so they could fit into the free-tier, crypto-middleman, or stolen-keys categories. QUIETVAULT is a twist on the stolen-credential method, using an on-host AI session instead of just a key. PROMPTLOCK is different because it uses a local model and only works on one victim at a time, so it doesn’t fit into the four main routes and isn’t discussed further.
Conclusion
Across four routes: offensive LLMs for sale, free-tier and keyless public APIs, hardcoded keys in distributed artifacts, and exposed LLM servers on victim infrastructure, the most durable access is the last one. The precondition for abuse is almost never a sophisticated exploit. It is an unauthenticated port facing the internet.
AI is the defining technology of this moment. It extends what a single person or small team can do and accelerates work that used to take weeks. AI is being integrated into more and more areas, from personal agents and email writing to some vulnerability research. The wow factor is real. But an LLM server is still a service running on a host. It listens on a port, speaks a protocol, and has an attack surface. The failure modes in this report; misconfiguration, leaked credentials, unpatched CVEs, open ports, are the same ones that produced years of incidents on Docker, Kubernetes, cloud storage, Redis, Elasticsearch, and bare Linux servers. The tooling is new. The mistakes are not.
Two things follow. The operator is still responsible for the basics: authenticate the service, keep it off the public internet unless there is a reason to expose it, patch the known CVEs, and audit what is running. These are not AI-specific requirements. They are the same ones we have been making for every networked service. An exposed Ollama instance serving a stranger’s prompts is not a failure of the model or the vendor that shipped it. It is a failure of whoever put it on the internet without a password. You broke it. You pay for it.
IOCs
| SHA-256 | Payload |
|---|---|
| ecd3b1a0e4832f1dc72be84c3c838ae4e29637c1cff4bfa70649cda90fa7a8ce | Mimikatz binaries (carrying AI API keys) |
| 153d7cdca3cb96023a2ee8e3de49b29ced60ffc865da04c3c6ef2b445b056d8f | |
| 0c1a409dd791ee8f7e157c455d9c35671bd81d17b562c7acd73f9f26401533ba | |
| a9dc00aeae6c245d76d873e675b555f044ecf94a5ece031a1e6ca30223beb905 | Malicious binary without family attribution (carrying AI API keys) |
| 99308a3f00490e8138974faafa3ea5ae089459b2500e097ccc0ed042b6a0c2af | SolarMarker (HuggingFace key) |
| 796e81c1b31f443ab3437663af97fe41b25bbf8ab7abcd0637238a568b66aa9d | SystemSettings.exe (OpenAI, Replicate, Voyage keys) |