Code reuse analysis vs. signature-based detection
We are often asked the question, “what sets your approach apart from other malware detection solutions?”
To further explain how code reuse analysis is different from signature-based detection approaches, let’s take a look at four Mirai samples which were uploaded recently to VirusTotal.
Our research team has come across a series of interesting malware samples which were uploaded to VirusTotal by the same user within an hour. Adversaries often use VirusTotal and other multi-engine platforms to test their malware for detection. These samples are most likely a byproduct of this sort of testing by an attacker.

Detection rates of the four samples uploaded to VirusTotal:
1st file has 24 detections
2nd file has 1 detection
3rd file has 6 detections
4th file has 0 detections
The screen capture above, taken from VirusTotal, indicates that the first file was detected by 24 engines as malicious. The remaining three files have very low to non-existent detection rates, posing the risk that they could fly under the radar in a future attack.
It’s clear that the attacker has modified their tools in order to stay evasive and is continuing to test the detection rate with new and modified samples.
Before we attempt to determine what changes the attacker made to the malware to evade detection, let’s take a look at the genetic analysis of each file. Below are four analyses taken from our genetic malware analysis platform, Intezer Analyze:
- Mirai code with statically linked libraries (VT detections: 24/60)
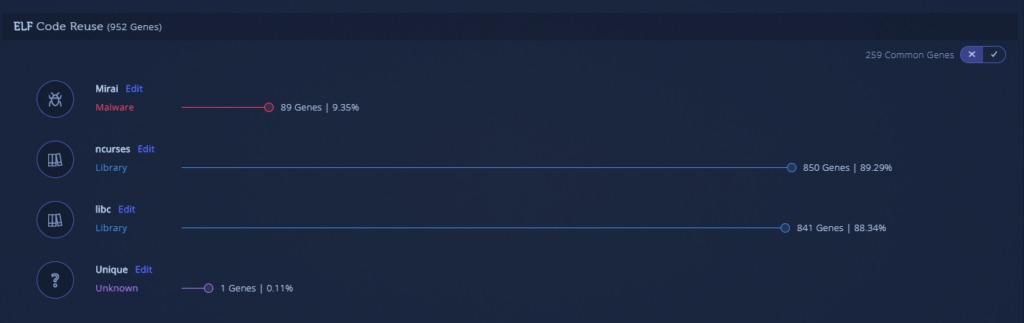
- Mirai code with encrypted strings, however, the decryption mechanism was not incorporated so this appears to be a test to see if the new strings will affect the detection rate (VT detections: 1/60)

- The attacker incorporated a working decryption routine, however, they forgot to strip the binary (remove function names and debug strings) so some vendors successfully detected this binary. Also, the attacker chose a different compiler to generate different code, resulting in more malicious genes (VT detections: 6/60)
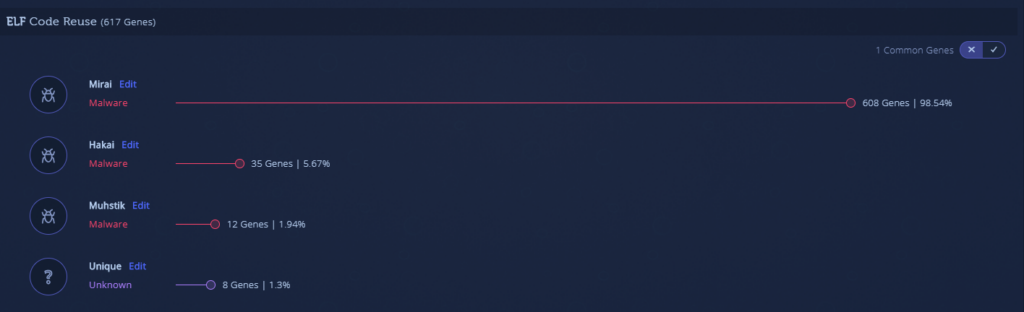
- Final version, strings encrypted and decryption routine works well. The binary is also stripped this time and statically linked, resulting in a fully undetected binary (VT detections: 0/60)
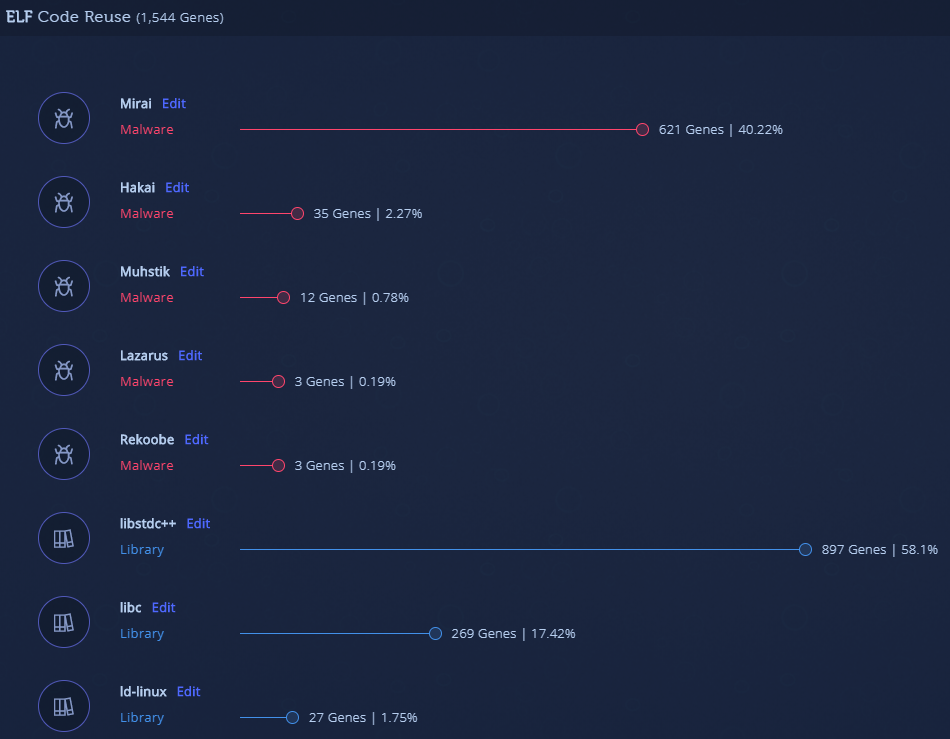
As we can see, the evolution of these malware samples does not impact Intezer Analyze’s ability to detect malicious code. As a result, all four samples were detected as malicious and classified to the Mirai malware family, within seconds.
Technical analysis
At first glance we can see two distinct pairs. Each file within its respective pair contains a nearly identical genetic makeup. The first pair is identical from a code perspective, with the same amount of genes and threat classification: Mirai. Please note the file names of the initial uploads:
- x86__64__lsb__unix-system-v__gcc-4.9.0__O3__no-obf__stripped__mirai-1.0__bot
- x86__64__lsb__unix-system-v__gcc-4.9.0__O3__no-obf__stripped__mirai-1.0__bot.obf
The file names suggest that we got the Mirai classification right in both samples — however, keep in mind that file names can be misleading. More importantly, we can assume that some type of obfuscation was used in the second file — both because of ‘obf’ in the file name and also because of the low detection rate.
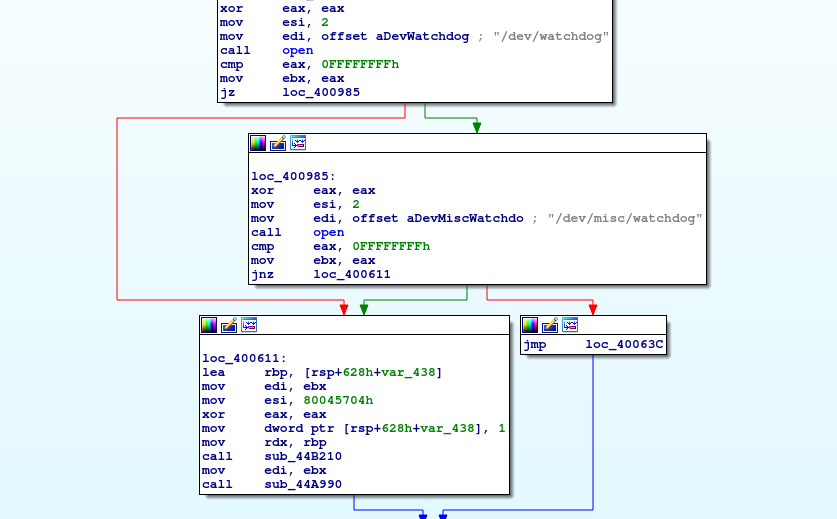
The second pair is also very similar. This time, there are no revealing file names. The main difference between the files is the method of library linking. We can understand that file number 4 is statically linked due to the amount of libc genes present, unlike sample number 3, which includes only the malicious payload. Apart from this difference, the [malicious] Mirai code is shared between both files.
Let’s dive further into the samples and spot the subtle difference between these files:
-
-
- Normal Mirai sample has clear text strings
 Please note the strings located in these code blocks. They are referring to paths in the Linux file system and they are readable. Remember, this is the sample with the high detection rate.
Please note the strings located in these code blocks. They are referring to paths in the Linux file system and they are readable. Remember, this is the sample with the high detection rate.
- Normal Mirai sample has clear text strings
- ‘Obfuscated’ Mirai sample has encoded strings

-
This file contains the exact same code, but what happened to the strings? Just take each letter and jump one letter forward. For example, d » e. And replace any slash (/) with a zero:
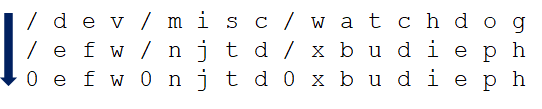
So, changing the strings is how the malware went from 24 detections to 1 detection.
Now, what about the second pair?
The 3rd file’s strings were encoded as well. However, the author behind this malware kept the function names as they were, which explains why it was recognized by six engines:

In the 4th and last file, the function names were stripped, which resulted in 0 detections:

Since code reuse analysis does not take strings into consideration during the classification process, these changes did not impact Intezer Analyze’s ability to detect the threat.
Go beyond IOC and signature-based detection
With an emphasis placed on protecting Windows endpoints, the antivirus industry is struggling to detect Linux threats. In a recent study conducted by researchers at Team CYRU, 78% or 6,931 known Linux threats were undetected by top-30 AV products.
Organizations require a tailored solution for Linux rather than an adapted Windows technology. You can read more about Mirai, the central role its code plays in the Linux threat ecosystem and how code reuse analysis presents an effective way to detect Linux threats, in our recent blog post: Intezer Analyze Community 2019 Recap
Linux threat implications on cloud security
The Linux operating system accounts for nearly 90 percent of all cloud servers. With companies increasingly storing their most sensitive information on the cloud, we expect Linux threats will pose a significant risk to enterprise security in the near future.
IOCs
4f2f4d758d13a9cb2fd4c71e8015ba622b2b4c1c26ceb1114b258d6e3c174010
058c2c0fbb516fb073558a2e48c77b466dfcf8b3aa3dd6dc3a9167d6b57f1d23
82ee41ec73fa5380bf29fbba1354ff84ea837058a0c9e770cfcbe5ba347c36cb
1fc49503c92bce012cc9210a0490fb3657ff9177d342ce61a86dbabd530b7a15