October 2023 Update: Intezer analyzes all URLs that we collect as evidence for automated alert triage, which now includes detecting and extracting QR codes for phishing email investigations.
At Intezer, we recently launched a URL analysis feature that will allow detecting phishing or malicious URLs.
To do so, we have multiple integrations with services such as URLscan and APIVoid, and additionally, we are adding in-house built tools and an update to public API so you can integrate Intezer into your organizations’ phishing investigation pipelines.
The aim of the first part of this two-part blog series is to introduce you to some common URL manipulation techniques and the URL structure. In part 2, when we’ll shed some light on how machine learning can prove useful for detecting phishing or malicious URLs.
The techniques we are going to review in this part of the blog are focused on human-detectable techniques, which you could use for links you receive in emails. Some of these techniques can help you spot URL manipulation before you click on links, without the need for any additional resources or requests.
Breaking Down the Structure of a URL
Let’s start with a little exercise.
Out of the following URLs, which one would you click on?
- ftp://ftp.microsoft.com/software/patches/fixit.exe
- https://www.micosoft.com/software/patches/fixit.exe
- http://securitycenter.microsoft.us.admin-mcas-gov.ms
Keep your answer in mind and let’s start investigating!
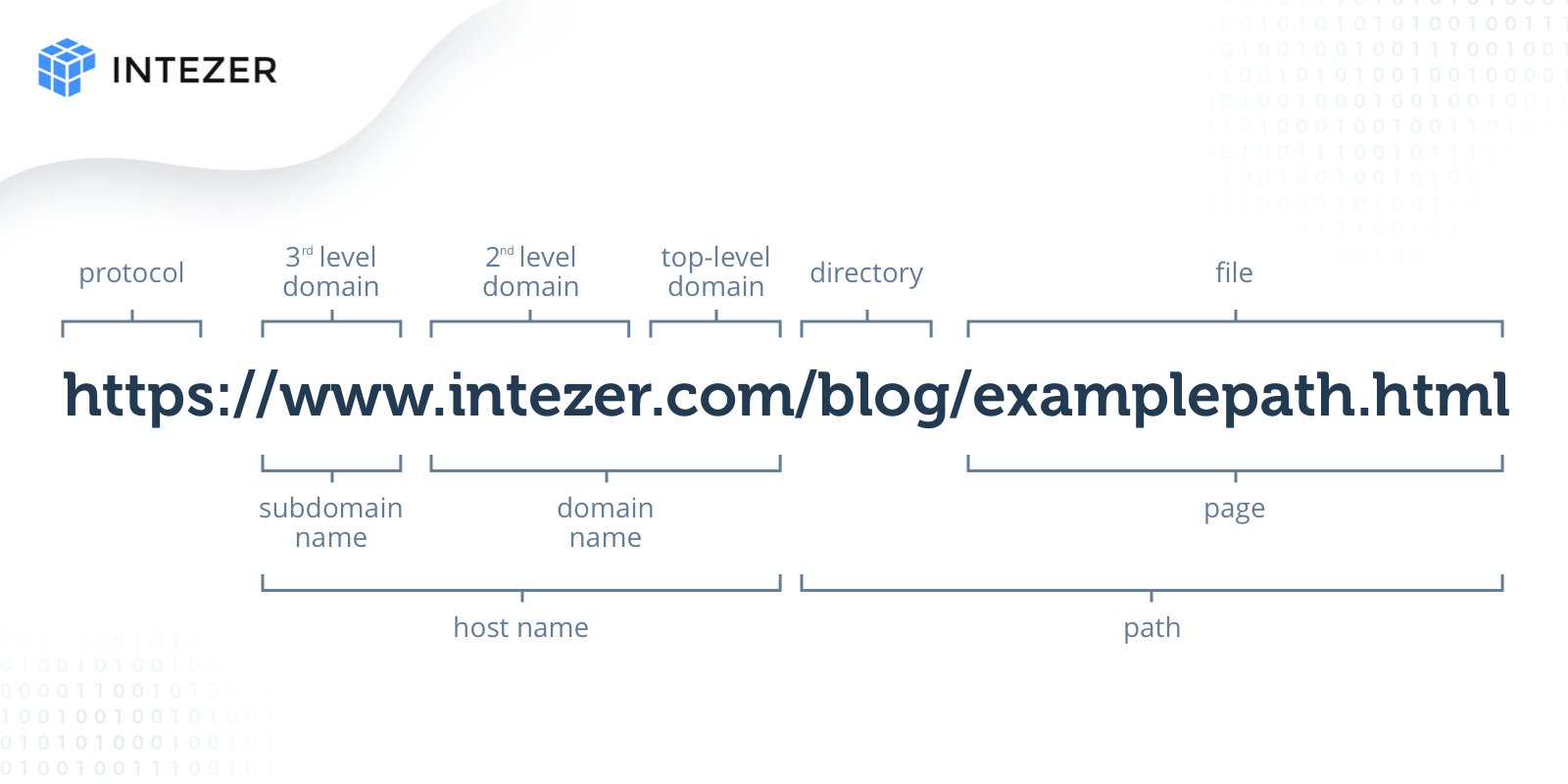
Let’s quickly describe the different parts of the URL (see fig 1):
- The protocol: describes the way a browser should retrieve information from a certain web source. What matters for us here is the distinction between HTTPS and HTTP which basically differ by being secure (or encrypted) and not secure. Another protocol to transfer files is FTP.
- The hostname: is made of the domain name and the subdomain name.
- The domain name consists of the second-level domain which is the name of your website and the top-level domain which specifies the type of website it is going to be, for example, .com is intended for commercial, .edu for educational and so on. The combination of the top-level and second-level domain is the only part that is unique in the URL and we can’t stress enough how important that is.
- The subdomain is like a specific “zone” inside your website. For example, you might have a URL like this: “your-organization.salesforce.com” which basically says salesforce has a sub-website for your organization.
- The path is basically like a path on your personal computer to a specific file. It indicates what resource you want to get from the website.
We will now leverage the URL structure to understand how to read a URL.
Let’s try with an example:
http://securitycenter.microsoft.us.admin-mcas-gov.ms
So this looks like Microsoft, right?
Well, it does if you assume that the fact that the word “microsoft” is inside the URL text is enough proof…
Let’s start discussing the domain name. The domain name is the only thing that is unique in each URL, so most of the phishing URLs are going to try to fool you into thinking the domain name is legitimate (while it is not).
The domain name is composed of the top-level domain and the second-level domain which appear before the path separated by a dot. In our “microsoft” example above the second-level domain is “admin-mcas-gov” and the top-level domain is “ms”.
So the correct way to read the URL, in this case, would be from right to left starting with the hostname on the right side. Doing so, we would immediately notice that the actual domain name we are going to be taken to is admin-mcas-gov.ms which has a subdomain called microsoft.
So this understanding is key for the rest of the blog: the actual website you are going to is, first of all, going to be defined by the unique domain name. (top-level + second-level domain)
So let’s revisit our previous exercise and analyze what the hell was going on there.
Basically, we are always going to ask ourselves, what is the domain for each URL?
First URL - ftp://ftp.microsoft.com/software/patches/fixit.exe
So this is actually our legit URL, so how was I trying to fool you? Well, I used the FTP protocol which is a completely legit protocol but less common. Here the domain or website we will land on is microsoft.com which is completely legit.
Second URL - https://www.micosoft.com/software/patches/fixit.exe
Well everything seems clean there except… OH wait a second there is an “r” missing so we actually get to a website called micosoft.com, this is not the domain we wanted.
Third URL - http://securitycenter.microsoft.us.admin-mcas-gov.ms
This one should be obvious by now: the actual website here is admin-mcas-gov.ms and not Microsoft.
So the answer was: The first URL is the real Microsoft one!
Hacking the Human Brain
Let’s review some manipulation techniques like the ones we discussed above and give them some really cool-sounding names and look at new examples. In every section, we are going to give some intuition about how to think about detecting those manipulations, and what suspicious attributes you could find by looking at a URL.
The general name we are going to give to URL manipulation is Cybersquatting (sounds cool right?).
Let’s give a formal definition:
The term cybersquatting refers to the unauthorized registration and use of Internet domain names that are identical or similar to trademarks, service marks, company names, or personal names (for example celebrity names).
Subdomain Cybersquatting
The problem:
We already have seen this kind of manipulation in our exercise with https://login.microsoft.activate-account.com/
The main “brain hacking” that is going on here is that we are used to reading English from the left to the right. As users are encountering the name “Microsoft” or any other big company name for that matter (Facebook, Instagram, etc.) in the URL, most users immediately tend to trust the URL.
Intuition:
There are multiple subdomains, some digits in there, and the URL (at least the hostname) is very long. Also, we notice that a popular brand name is inside one of the subdomains.
TLD (Top Level Domain) Cybersquatting
The problem:
Imagine you have a very nice company called “myamazingcompany” and you want to create a website, “https://www.myamazingcompany.com” and you register the domain “myamazingcompany.com”.
But after a while, you start getting complaints that your website is a phishing scam. Astonished, you investigate the issue and notice something peculiar about the website in question, it is “https://www.myamazingcompany.so” !! This means someone targeted your website by using a top-level domain you didn’t own “so” and was able to make customers believe that this is your company's website. (In our exercise above, number 3 used this technique.)
Intuition:
So one way to try to flag this kind of manipulation automatically is a basic heuristic stating the following: if the popular domain is found inside as second-level domain, but has a different top-level domain, then flag it as suspicious.
In general, big companies buy most of the top-level domains to prevent this kind of cybersquatting. But smaller companies often have a hard time keeping track of this.
Typosquatting
The problem:
This one is very basic, it basically means counting on people making typos when writing popular domain names. A couple of examples could be yutube, arifrance, goggle, facdebook, micosoft
Fun fact, the autocorrection module while writing this blog suggested correcting these typos multiple times.
Another closely related problem is similar-domain cybersquatting.
In this case, attackers are not only going to focus on typos but are going to focus on the similarity of the domain.
Some examples could be:
- cnn-news.com (added “-news”)
- Facebook1.com (Added the digit “1”)
- flarecloud.com (inverted the word order, instead of Cloudflare)
Intuition:
So we can intuitively already think of some ways to detect manipulations like these by keeping a list of very popular domains that are potential targets for phishing attacks like Facebook, Google, banks, credit cards, and many more.
Using this list we could test the string distance (e.g. Levenshtein distance) to each of the words in the popular domain list, if the string distance would be bigger than 1 but less than another value, we could assume that some malicious intent was present and flag it.
In addition, in the similar-domain cybersquatting case, we also notice there are digits inside some of the URLs or special characters like “-” that are rarer in trusted URLs. So flagging URLs for these might also make sense.
Additional Information: Suggestive Words
Another thing we would like to note about phishing URLs is that usually, they will try to get you to input your credentials for some service. That is why we can also raise the probability that something is phishing if we notice some suggestive words inside the URL, these could be words like “login,” “account,” “activate,” “bank,” and more…
This is easily detectable by again keeping a word list of suggestive words found in phishing URLs and seeing if they are included anywhere inside the URL. The same applies to a suggestive word list. A suggestive word would be a word that would raise the probability of the URL being connected to phishing. (“login,” “account,” “activate,” etc.)
Before we continue, let’s show off our new URL feature and test it on the third URL of the exercise, “http://securitycenter.microsoft.us.admin-mcas-gov.ms”
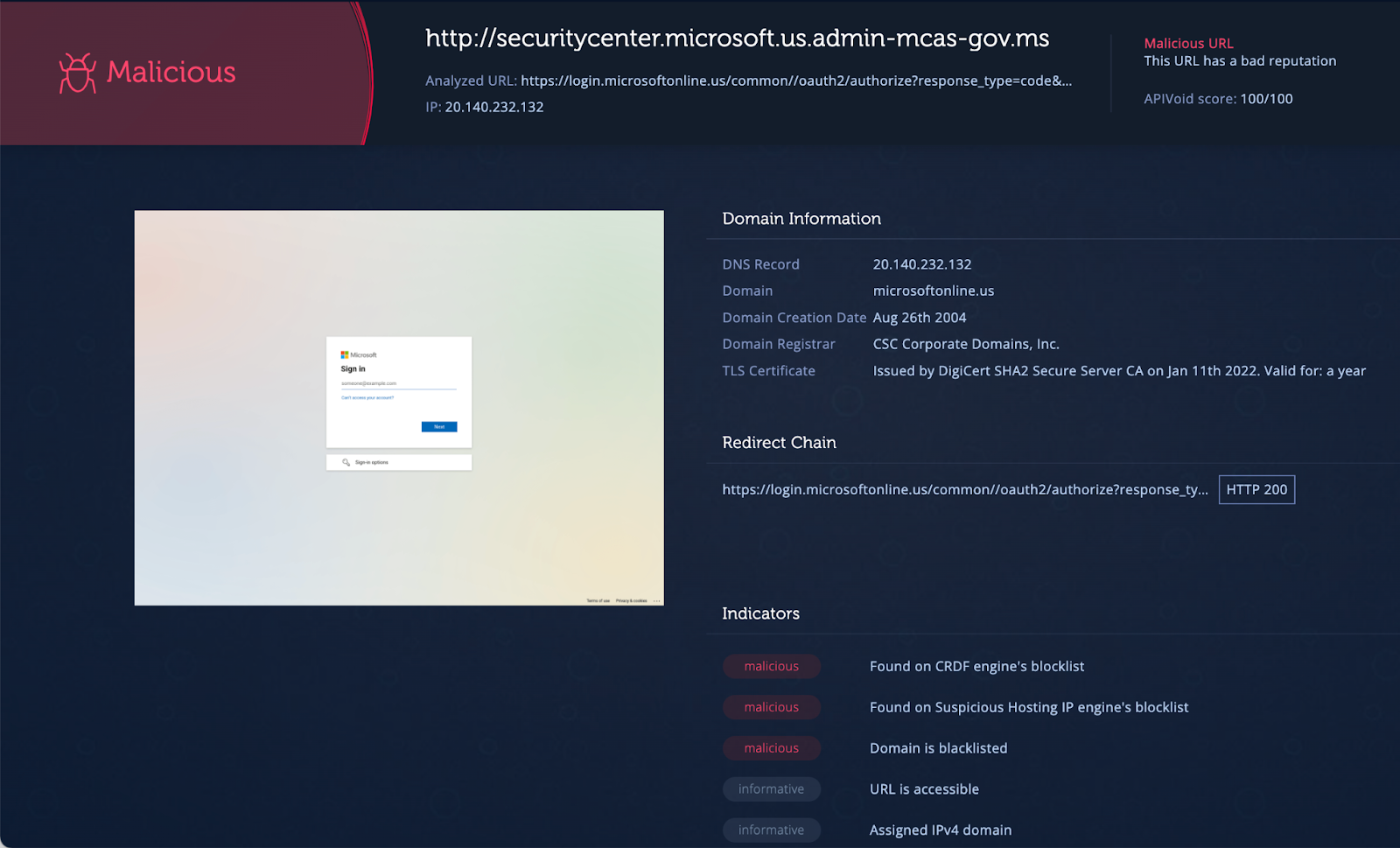
URL Analysis - https://analyze.intezer.com/url/5a70c8a2-2a7a-4f37-bfec-f82fcceca855
Hacking the Browser
Next I would like to discuss a slightly different kind of manipulation, which is based on browser behavior. I put these in a different section because they are mostly exploiting technology fallacies and less human fallacies as we saw before.
These techniques are still detectable by human intervention as we’ll demonstrate, but require more time if you are just clicking your way through the internet.
Also, they may require some basic HTML knowledge.
Use of special characters
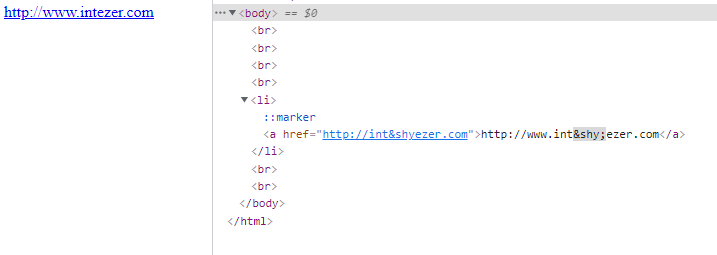
- The “Soft Hyphen” character or ­
So this is a rather weird manipulation, it leverages that HTML does not show the ­ character, like the actual URL the user is referred to, is http://int­ezer.com but the URL that is shown in the web page is
- Hex encoding & special login technique
Let's look at this URL: http://www.google.com:login@%69%6E%74%65%7A%65%72%2E%63%6F%6D
So here we are going to have two main techniques, the first one is hexadecimal encoding, in this case, the URL above is going to redirect us to intezer.com since that is the hexadecimal value I inserted above. How about the first part which led you to believe this was actually google.com?
Well, some websites allow you to log in by setting passwords and usernames inside the URL itself. If the website does not allow this it has no effect.
Let’s quickly investigate what’s going on:
- Protocol: HTTP (not secure)
- Login-username: www.google.com
- Login- password: login
- Actual website - intezer.com (written in hexadecimal)
Short URLs
Basically here you just hide the true URL by using a short redirect URL. In this fashion, is it possible to know what page you’re going to without clicking on the below link?
https://tinyurl.com/intezer-tiny
So in this case you have a couple of options:
- Use the preview feature these short URL services have, by putting “preview” between the https:// and the first word of the URL in the following fashion: https://preview.tinyurl.com/intezer-tiny They way you get redirected to a page of the url service which shows you the intended URL.
- Use a service like Intezer Analyze to scan the URL and get an analysis that tells you both what page the URL is redirecting to and if it is malicious.
- Use an “un-shorten” URL service like https://unshorten.it/
- Also, as a last resort, after clicking, you can take a look at the actual URL of the website you were directed to and search for manipulation techniques as we saw before.
HTML concealment
This one is pretty straightforward, this is just putting something different in the href than what is displayed by the HTML. You can discover this pretty quickly using the inspect panel.
An automatic way to detect this behavior could be done pretty simply by loading the HTML page and comparing all the href to the displayed text.

Of course, there are many other browser manipulations (Puny code for example) and suspicious features that can be extracted from the HTML of a website but they are not necessarily directly related to the URL itself so we will leave this out of scope for this blog.
Further Reading on URL Analysis
In this blog, we discussed how people with malicious intent can manipulate URLs to make us believe malicious URLs are trustworthy.
So now that we have seen how to visually identify URL manipulation, in my next post we’ll see how we can use some of the characteristics of these techniques for machine learning algorithms and get some intuition about how we could automatically flag some of these characteristics. Check out part 2 on URL analysis with machine learning.
Want to know the technical details about analyzing email content, QR codes, or using AI to investigate in phishing emails? More about those topics in our recent blog posts here:
Intezer
Count on Intezer AI SOC to triage, investigate and respond to every alert at unmatched speed and accuracy.
In this article
Share article
URL Analysis 101: A Beginner’s Guide to Phishing URLs
.png)
AI SOC
AI
Company News
5 minutes
Loop engineering comes to the SOC: Introducing the Intezer Org Brain
Organizational context in an AI SOC is table stakes. Org Brain is very different. It learns, it recalls, it fetches what it's missing, and it gets sharper with every alert it touches, all autonomously.

Detection Engineering
AI SOC
8 minutes
Detection engineering in the AI era
AI is lowering the barrier to sophisticated attacks. Explore why detection engineering matters and where most programs fall short.

AI SOC
CISO
Company News
Introducing Custom Agents: Automate your SOC, your way
Add your own agents and automations on top of the ones Intezer runs out of the box, take more of the manual work off your analysts, and tailor AI SOC to the way your team actually operates.